CerealsDB web services overview
These pages describe the web services that have been developed for CerealsDB to allow bioinformaticians to access CerealsDB data (currently SNPs, contigs and search terms for our KASP genotyping platform).
The CerealsDB webservices have been developed in collaboration with the Data Infrastructure & Algorithms group at the Earlham Institute and we would like to thank Rob Davey, Simon Tyrell and Xingdong Bian for their help setting up these services.
This part of the site has been written with software developers in mind, and may therefore appear rather esoteric to some of our users. If you aren't familiar with command lines and writing code, you may find yourself out of your depth, but I hope this page will at least impress upon users the power of web services for data integration and standardisation, which is a pressing need in the wheat community where information is stored on disparate databases around the world.
We have created a web service based on REST Architecture (RESTful web services). A web service is a collection of open protocols and standards that are used to exchange data between applications or systems. Software applications written in a variety of programming languages and running on various platforms can use web services to exchange data over computer networks such as the Internet. This interoperability (e.g., between Java and Python, or Windows and Linux applications) is due to the use of open standards such as JSON.
The CerealsDB web services use HTTP methods to implement the concept of REST architecture. A RESTful web service usually defines a URI, Uniform Resource Identifier a service, provides resource representation such as JSON and a set of HTTP Methods.
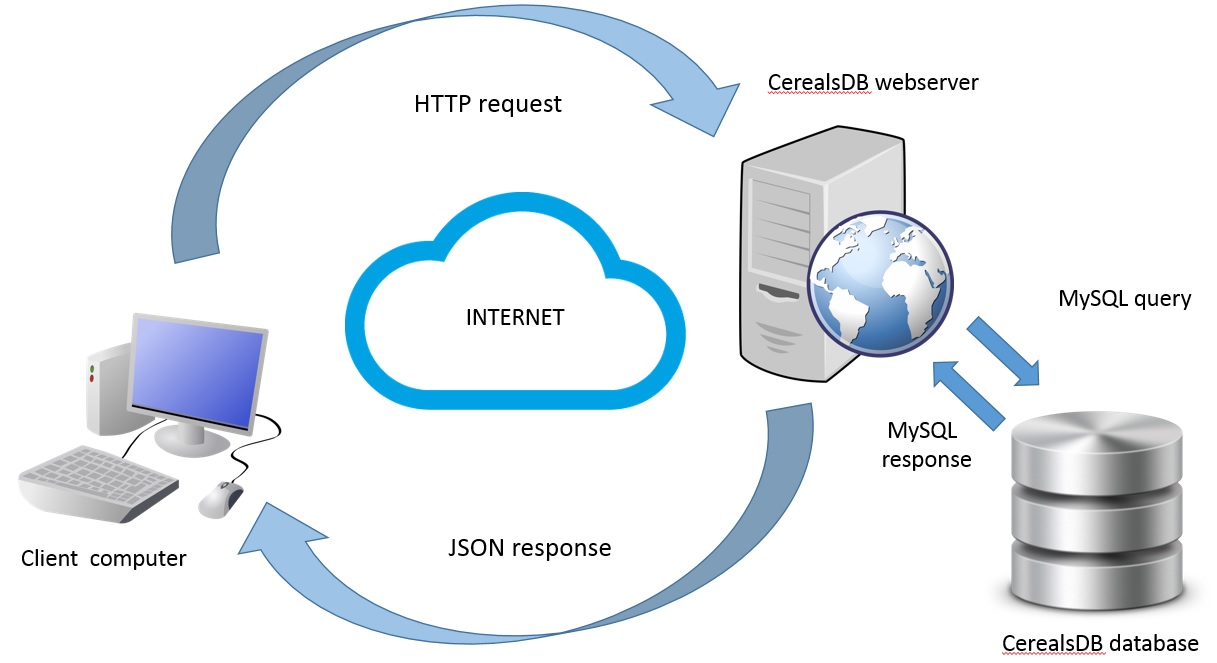
The diagram shows a simple request made by a client computer across the web in the form of an HTTP request which contains information encoded in JSON. The CerealsDB webserver then interprets this request and queries CerealsDB. The response is converted into JSON and returned to the client computer, where the information embedded in the JSON code can be parsed.
Based at the University of Bristol with support from BBSRC.
![]()
![]()